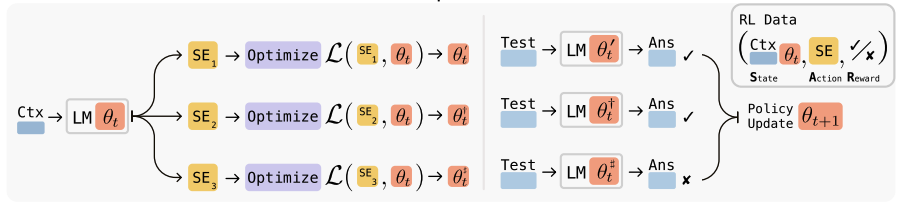
Self-evolving Large Language Models (LLMs) mark a fundamental paradigm shift in artificial intelligence. Unlike traditional models with static weights after training, these models can automatically adjust their weights as they receive new information.
Recent breakthroughs, such as Massachusetts Institute of Technology’s SEAL (Self-Adapting Language Models, 2025 – https://arxiv.org/pdf/2506.10943), demonstrate how LLMs can autonomously generate novel training datasets by synthesizing external knowledge, discover architectural optimizations, and enable continual learning without explicit human retraining cycles. This closed-loop self-improvement uses gradient-based meta-learning combined with reinforcement signals derived from the model’s own outputs to dynamically refine both parameters and architecture.
This capability introduces complex technical challenges that push AI infrastructure beyond conventional static training:
– Adaptive compute orchestration: Continuous self-training demands compute clusters that can dynamically allocate resources based on the model’s self-assessment, workload diversity, and shifting data distributions.
– Robust, real-time data pipelines: Data ingestion must seamlessly handle auto-curated, model-generated datasets, with quality controls driven by uncertainty estimation and anomaly detection to prevent drift and catastrophic forgetting.
– Stable optimization frameworks: Achieving convergence in models that modify their own architecture and loss functions requires new theoretical and practical frameworks to ensure stability and robustness amid non-stationary objectives.
At AICONIC VENTURES, we center our investment thesis on these critical frontiers.
For innovators advancing the autonomous AI stack or unlocking its application potential, let’s connect – email us at contact@aiconicventures.com. The future of AI leadership belongs to those pioneering safe, scalable self-evolving intelligence.
Thank you the team at MIT’s Scale ML especially Adam Zweiger and Jyo Pari for a great research paper.